SageTea AI Risk Engine
Purpose
Risks are probabilities (chances) of something occurring. If they have a negative outcome, we consider them to be potential problems. On the other hand, if they would have a positive outcome, we call these opportunities. Business people weigh and measure risks and opportunities all the time. We take them into account when planning things like sales, projects, human resources, finance, relationships, and nearly every aspect of life. This AI is designed to read text in documents and provide insights as to what the risks (and opportunities) they contain could be. Our new version has been upgraded to work beyond just handling audit reports, it can now work for any type of business.
How It Was Developed
The SageTea AI Risk Engine is a next generation AI that is trained to analyze risks in unstructured data. It is based on a joint project by the University of New Brunswick, SageTea, and CAAF with funding provided by Lockheed Martin – Security Risk and Control Modeling for Deep Learning using the SAGETEA Methodology.
How It Works
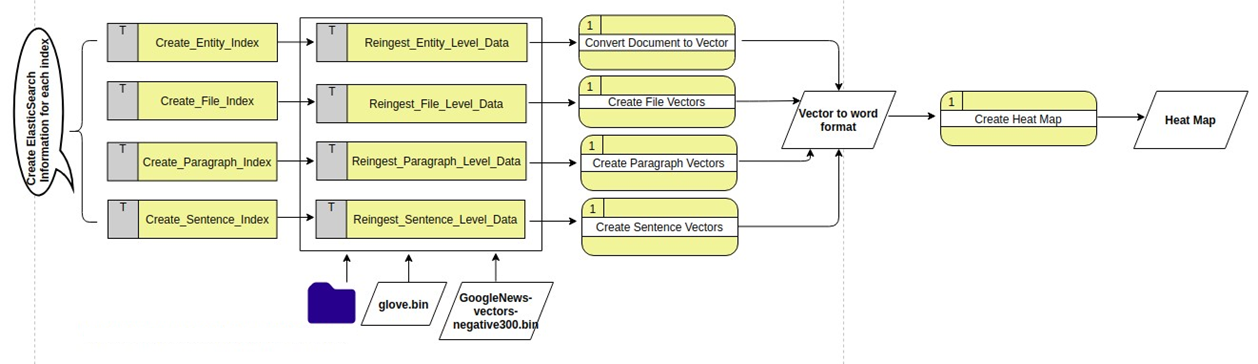
The engine works by ingesting files, parsing them into Entities, File (Indexes), Paragraphs and Sentences. The architecture is shown in the following diagram. This uses Word2Vec to then generate a Heat Map.
This new AI engine is available with low code AI apps made using Text To Software.
Word2Vec Model
Word2Vec is a statistical method for efficiently learning a standalone word embedding from a text corpus
developed by Tomas Mikolov, et al. at Google in 2013. It is responsible to make the neural-network-based
training of the embedding more efficient.
Two different learning models were introduced that can be used as part of the word2vec approach to learn the
word embedding; they are:
• Continuous Bag-of-Words, or CBOW model.
• Continuous Skip-Gram Model.
The CBOW model learns the embedding by predicting the current word based on its context. The continuous skip-gram model learns by predicting the surrounding words given a current word. Both models are focused on learning about words given their local usage context, where the context is defined by a window of neighboring words.
The key benefit of the approach is that high-quality word embeddings can be learned efficiently (low space and time complexity), allowing larger embeddings to be learned (more dimensions) from a much larger corpora of text (billions of words).